[한빛미디어] 혼자 공부하는 데이터 분석 with 파이썬
좋은 개발자는 컴퓨터를 분석의 대상으로 바라볼 뿐, 두려워하지 않는다!‘전공서가 너무 어려워서 쉽게 배우고 싶을 때’, ‘개발자가 되고 싶은데 뭐부터 봐야 하는지 모를 때’ ‘기술 면접
hongong.hanbit.co.kr
열 삭제하기
loc 메서드와 블리언 배열 이용하여 삭제하기

데이터에서 손상되거나 부정확한 부분을 수정하고, 불필요한 데이터를 삭제하거나 불완전한 갑을 교체하는 등의 작업을 데이터 정제라고 한다.
저장한 csv 파일을 불러왔을 각 라인으 끝에 콤마(,)가 있는 경우가 있다. 불필요한 열이므로 삭제하는 것이 좋다.
import pandas as pd
# `low_memory = False` 설정을 사용하면 pandas가 CSV 파일을 한 번에 읽어들임
# 메모리 사용량이 증가하지만 큰 파일이라 하더라도 데이터 타입 추론이 일관되게 이루어짐
ns_df = pd.read_csv('ns_202104.csv', low_memory = False)
ns_book = ns_df.loc[:, '번호':'등록일자']
ns_book.head()
loc 슬라이싱을 사용하여 마지막 열을 제외하고 새로운 데이터프레임을 만들 수 있다.
만약 중간에 있는 열을 제외하는 경우라면 원소별 비교를 통해 얻은 불리언 배열을 이용하여 새로운 데이터프레임에 적용할 열만 선택하여 가지고 올 수 있다.
selected_columns = ns_df.columns !== 'Unnamed: 13'
ns_book = ns_df.loc[:, selected_columns]
drop() 메서드 이용하여 삭제하기
ns_book = ns_df.drop('Unnamed: 13', inplace = True, axis = 1)
ns_book.head()
# 여러 개의 열을 제외할 때
ns_book = ns_df.drop(['부가기호', 'Unnamed: 13'], inplace = True, axis = 1)
ns_book.head()
dropna() 메서드 이용하여 삭제하기
dropna() 메서드는 기본적으로 NaN이 하나 이상 포함된 행이나 열을 삭제한다.
ns_book = ns_df.dropna(axis = 1)
# 행에 있는 모든 값이 NaN인 열만 삭제하기
ns_book = ns_df.dropna(axis = 1, how = 'all')
ns_book.head()
행 삭제하기
dorp() 메서드, dropna() 메서드에 axis = 0을 적용하면 열을 삭제할 때와 동일하게 행을 삭제할 수 있다.
슬라이싱이나 불리언 배열을 []에 전달하여 행을 선택할 수 있다.
# 불리언 배열 이용하기
selected_rows = ns_df['출판사'] == '한빛미디어'
ns_book2 = ns_book[selected_rows]
ns_book2.head()
# loc 메서드에 불리언 배열을 이용해도 같은 결과를 얻을 수 있다.
# [selected_row]과 [selected_row, :]은 동일한 결과를 반환한다.
ns_book2 = ns_book.loc[selected_row]
ns_book2.head()
# 대출 건수로 불리언 배열 만들기
ns_book2 = ns_book[ns_book['대출건수'] > 1000]
ns_book2.head()
중복된 행 찾기
판다스의 중복된 행은 duplicated() 메서드를 사용한다. 기본적으로 중복된 행 중에서 처음 행을 제외한 나머지 행은 True를 반환한다.

# subset 매개변수를 이용한 중복 행 찾기
# 'keep = False'로 지정하면 모든 중복된 행을 True로 표시한다.
ns_book.duplicated(subset = ['도서명', '저자', 'ISBN'], keep = False)
그룹별로 모으기
groupby()
그룹화는 groupby() 메서드를 사용한다.
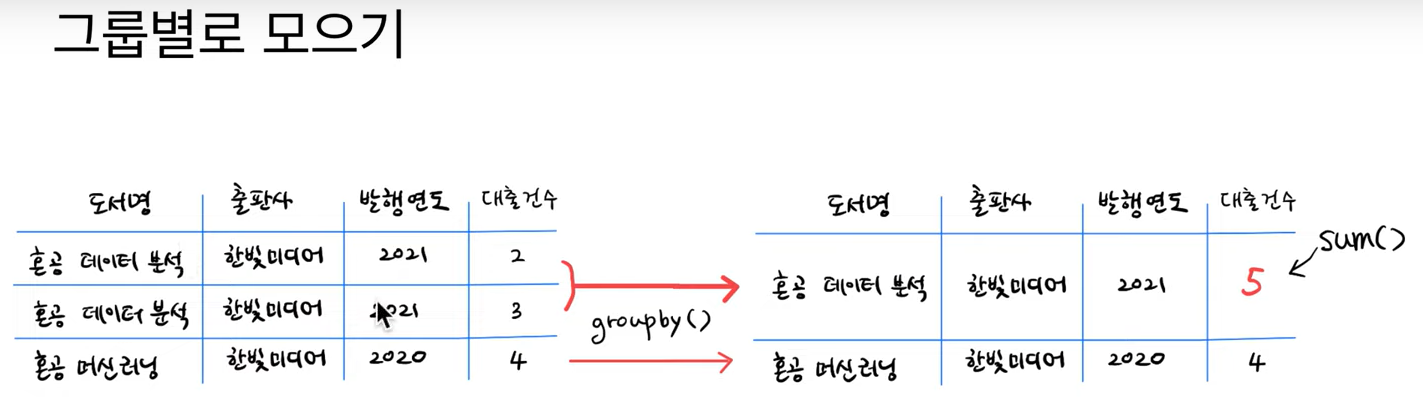
groupby() 메서드는 지정된 열에 NaN이 포함되어 있으면 해당 행을 삭제한다. 이번 예시에서는 대출건수를 구하는 것이기 때문에 실수로 누락되어 있는 값을 모두 포함하기 위해 dropna = False로 지정한다.
# dropna 매개변수를 False로 지정하면 지정된 열에 NaN이 포함되어 있어도 삭제하지 않는다.
loan_count = count_df.groupby(['도서명', '저자', 'ISBN', '권'], dropna = False).sum()
일괄 함수 만들기
def data_cleaning(filename):
ns_df = pd.read_csv(filename, low_memory = False)
ns_book = ns_df.dropna(axis = 1, how = 'all')
count_df = ns_book[['도서명', '저자', 'ISBN', '권', '대출건수']]
loan_count = count_df.groupby(['도서명', '저자', 'ISBN', '권']), dropna = False).sum()
dup_rows = ns_book.duplicated(subset = ['도서명', '저자', 'ISBN', '권'])
unique_rows = ~dup_rows
ns_book3 = ns_book[unique_rows].copy()
ns_book3.set_index(['도서명', '저자', 'ISBN', '권'], inplace = True)
ns_book3.update(loan_count)
ns_book4 = ns_book3.reset_index()
ns_book4 = ns_book4[ns_book.columns]
return ns_book4
데이터 수정하기
누락된 값 확인하기
판다스의 데이터프레임에서 info() 메서드를 사용하면 누락된 값이 있는 행 개수를 확인할 수 있지만 조금 번거롭다. isna() 메서드를 사용하면 NaN을 직접 확인할 수 있다.
ns_book4.isna().sum()
데이터 타입 변경하기
실수형 데이터를 정수형 데이터로 바꾸기 위해 astype() 함수를 사용하고 매개변수를 딕셔너리 형식으로 전달한다.
ns_book4 = ns_book4.astype({'도서권수':'int32', '대출건수': 'int32'})
누락된 값 바꾸기
누락된 값을 확인하는 isna() 함수를 이용하여 불리언 배열을 만들고 최종적으로 누락된 값을 원하는 값으로 바꿀 수 있다. 이때 fillna() 메서드를 사용한다.
# loc 활용
set_isbn_na_rows = ns_book4['세트 ISBN'].isna()
ns_book4.loc[set_isbn_na_rows, '세트 ISBN'] = ''
# fillna() 메서드 활용
ns_book4.fillna('없음')
replace() 메서드를 활용할 수 있다.
ns_book4.replace(np.nan, '없음').isna().sum()
# 바꾸려는 값이 여러 개일 때는 딕셔너리 형식으로 지정한다.
ns_book4.replace({np.nan:'없음', '2021':'21'}).head()
정규 표현식을 활용한 값 바꾸기
정규 표현식은 문자열 패턴을 찾아 대체하기 위한 규칙의 모음이라고 할 수 있다.
| 정규 표현식 | 의미 | 패턴 | 의미 |
| \d | 숫자 | \d\d\d\d | 네 자리 연도 |
| () | 그룹 | \d\d\(d\d) | 세 번째, 네 번째 숫자 |
| {} | 반복 | \d[2](\d[2]) | 반복 |
| . | 문자 1개 | ||
| * | 문자 0개 이상 반복 | ||
| \s | 공백 |
로런스 인그래시아(지은이), 안기순(옮긴이)
위의 문구에서 지은이와 옮긴이의 이름만 남길 수도 있다.
# 발행년도 수정하기
ns_book4.replace({'발행년도':{r'\d\d(\d\d):r'\1}, regex = True}[100:102]
# 문자 찾기
ns_book4.replace({'저자':{r'(.*)\s\(지은이\)(.*)\s\(옮긴이\)':r'\1\2'}, {'발행년도':{r'\d[2](\d[2])':r'\1'}}, regex = True)[100:102]
정규 표현식 앞의 r은 파이썬에서 정규 표현식을 다른 문자열과 구분하기 위해 접두사처럼 붙인 것이다. 동일한 정규 표현식이 반복될 때는 일일일 쓰는 대신 중괄호를 사용하여 개수를 지정한다.
contains() 메서드 사용하기
contains() 메서드는 시리즈나 인덱스에서 문자열 패턴을 포함하고 있는지 검사한다. contains() 메서드의 na 매개변수를 True로 지정하면 누락된 행을 True로 표시해 준다.
invalid_number = ns.book4['발행년도'].str.contains('\D', na = True)
ns_book4[invalid_number].head()
BeautifulSoup를 활용한 값 바꾸기
값이 누락되어 있거나 알 수 없는 행이 있는 경우 검색한 결과의 HTML 태그를 이용하여 값을 바꿔준다.
import requests
from bs4 import BeautifulSoup
def get_book_title(isbn):
url = 'http://www.yes24.com/Product/Search?domain=BOOK&query={}'
r = requests.get(url.format(isbn))
soup = BeautifulSoup(r.text, 'html.parser')
title = soup.find('a', attrs = {'class':'gd_name'}).get_text()
return title
import re
def get_book_info(row):
title = row['도서명']
author = row['저자']
pub = row['출판사']
year = row['발행년도']
url = 'http://www.yes24.com/Product/Search?domain=BOOK&query={}'
r = requests.get(url.format(row['ISBN']))
soup = BeautifulSoup.(r.text, 'html.parser')
try:
if pd.isna(title):
title = soup.find('a', attrs = {'class':'gd_name'}).get_text()
except AttributeError:
pass
try:
if pd.isna(author):
authors = soup.find('find', attrs = {'class':'info_auth'}).find_all('a')
author_list = [auth.get_text() for auth in authors]
auth = ','.join(author_list)
except AttributeError:
pass
try:
if pd.isna(pub):
pub = soup.find('span', attrs = 'class':'info_pub'}).find('a').get_text()
except AttributeError:
pass
try:
if year == -1:
year_str = soup.find('span', attrs = {'class':'info_date'}).get_text()
year = re.findall(r'\d{4}', year_str)[0]
except AttributesError:
pass
return title, author, pub, year